
Craxel's Black Forest Database (BFDB) uses a multi-dimensional hash to drive O(1), big data lookups across multiple data modalities. BFDB enables the fusion of time-series, graph, and geospatial data models in a single structure, supporting analytics at petabyte (PB) and exabyte (EB) scale. We offer a cloud solution on Amazon Web Services (AWS), and our solution follows the AWS Well Architected Framework.
If you think of a car analogy, BFDB supplies a premiere, best-in-class engine, while AWS provides the suspension, body, seats, and tires. This allows our engineers to focus on unlocking the features of our platform, vs. dealing with infrastructure.
This blog post describes our architecture approach, and how our decisions conform to the AWS Well Architected Framework: Operational Excellence, Security, Reliability, Performance Efficiency, Cost Optimization, and Sustainability.
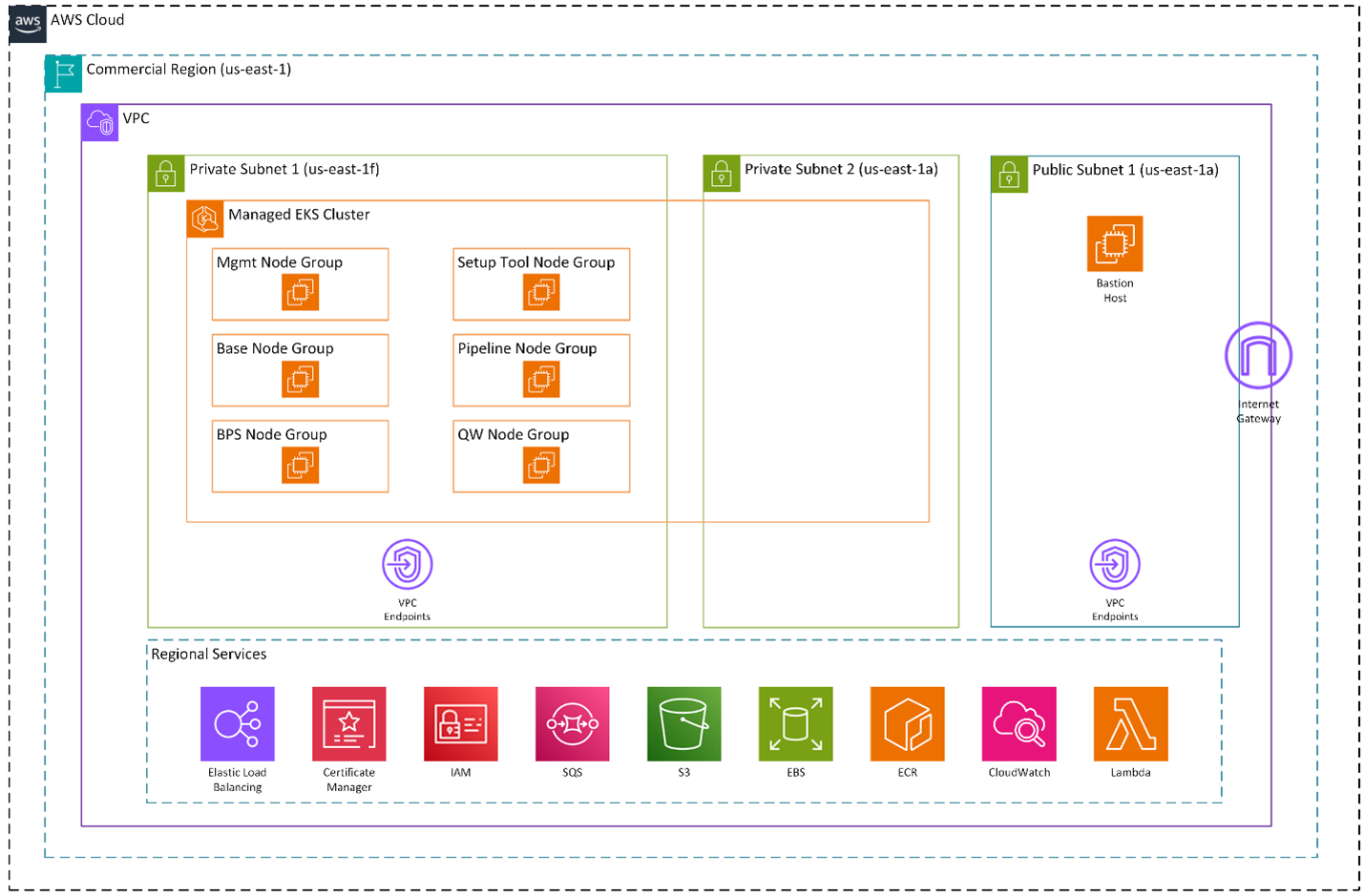
BFDB runs inside of your dedicated Virtual Private Cloud. A managed Amazon EKS cluster operates in private subnets across two availability zones. Node groups separate management services, base services, BPS workloads, pipelines, setup tooling, and query services. A bastion host in the public subnet provides controlled administrative access.
The platform users standard AWS primitives around the cluster: Elastic Load Balancing, AWS Certificate Manager, IAM, VPC Endpoints, Amazon SQS, Amazon S3, Amazon EBS, Amazon ECR, Amazon CloudWatch, and AWS Lambda.
AWS runs the infrastructure that allows BFDB to provide the ingest pipeline, graph construction, vector indexing, and query engine.
We designed a horizontally scalable system with commodity services, for growth and fast response times.
BFDB must support simultaneous ingest, graph construction, and queries. In practice, BFDB runs ingest pipelines, query services, and platform services on separate node groups in Amazon EKS. EKS provides controlled rollout, workload separation, and visibility when something drifts. We follow standard DevOps practices and push new images to Amazon ECR when needed. Kubernetes replaces the pods for the updated services without impacting the system. We capture Telemetry through Amazon CloudWatch, which includes logs and metrics from each service.
We follow NIST 800-53 and keep BFDB layers separate, with a principle of lease privilege.
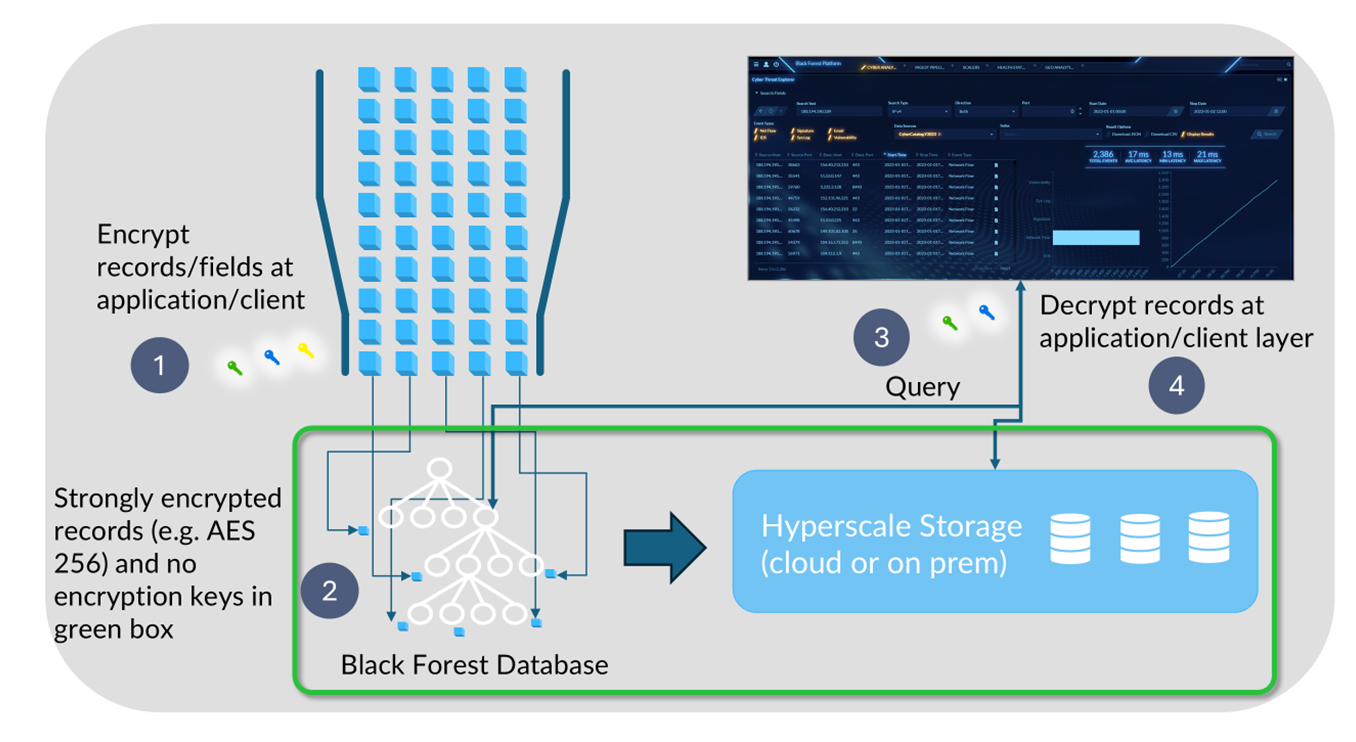
In BFDB, every record carries a security label. Attribute-Based Access Control (ABAC), mandatory controls, and searchable (key) encryption enforces access at the data layer. In AWS, the runtime lives in private subnets with narrow Identity Access Management (IAM) permissions, VPC endpoints, managed certificates, and a single controlled admin path. Only those with proper access can see certain records.
In short, BFDB secures the records and AWS secures the runtime.
Our Architects expect and design for failure. We build a robust system with a small blast radius.
Users demand 24/7 ingest and long-lived history. BFDB indexes on ingest, keeps deep history online, and supports fast query across that history. AWS keeps the backlog stable, keeps the services healthy, and recovers cleanly when a node disappears. Multi-AZ placement, SQS-backed stages, and durable storage in S3 and EBS turn an instance failure into a retry instead of system failure.
BFDB pipelines exchange work through Amazon SQS. Workers pull tasks from the queue and process them independently. If a worker disappears, another worker continues processing the backlog.
The cluster runs across multiple AZs. Kubernetes replaces failed containers automatically and Elastic Load Balancing routes requests to healthy query services. Data and intermediate artifacts live in Amazon S3, while stateful services use Amazon EBS volumes.
AWS prevents throughput-heavy work from stealing resources needed for latency-sensitive work. Ingest spikes do not slow down queries.
Query traffic enters through Elastic Load Balancing and runs on the query node group in Amazon EKS. Pipeline workers pull work from Amazon SQS and run on the pipeline node group. Containers deploy from Amazon ECR, and Amazon CloudWatch tracks CPU, memory, and queue depth to anticipate potential resource contention.
When ingest volume rises, the pipeline node group expands and ingest/ query capacity remains unchanged.
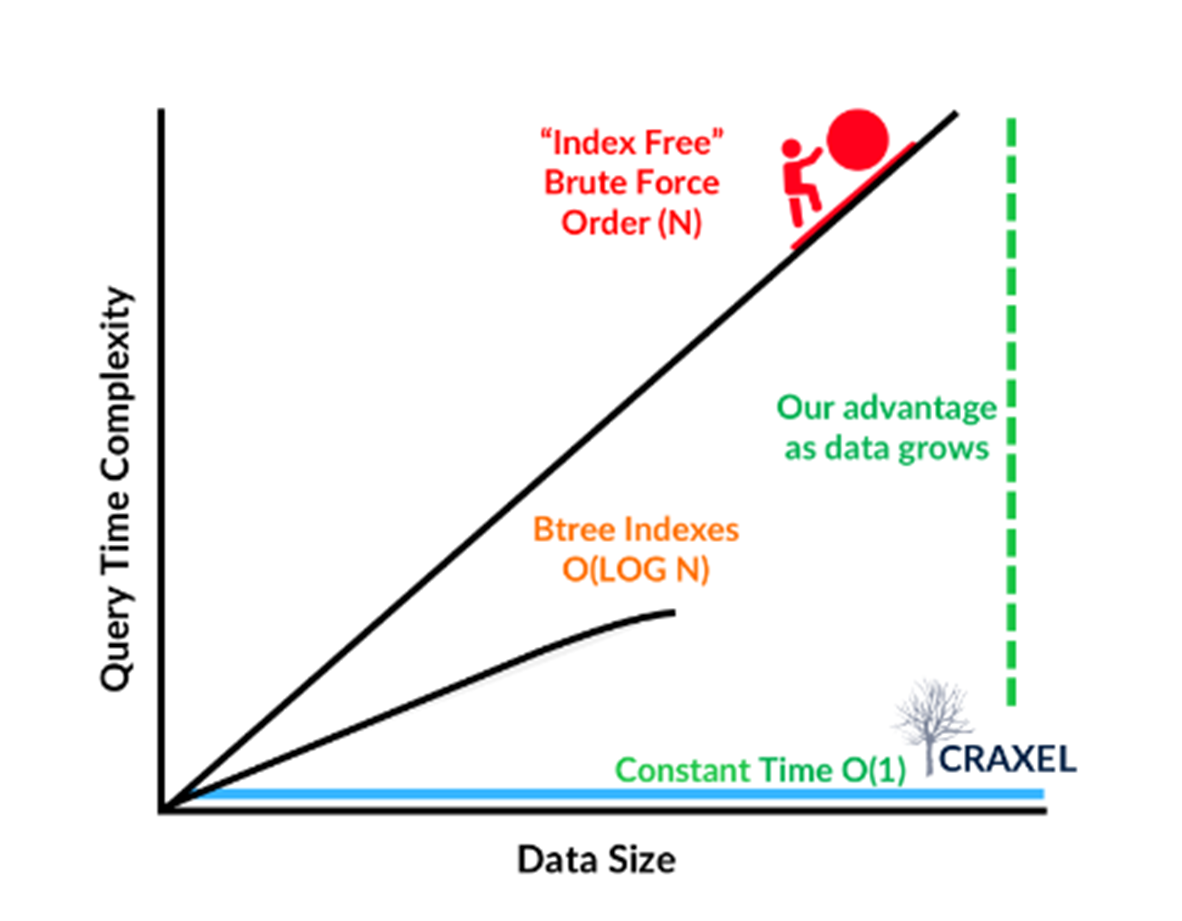
Our O(1) algorithm provides optimizations that makes all data stored in BFDB either hot (EBS) or warm (S3) regardless of tiering. We do not need the user to lifecycle-manage data into "cold" (tape) storage. Traditionally, other DB services become expensive at scale, and drive Data Engineers to archive data outside of the system, often re-ingesting this data for any archival analysis. The legacy concept of cold storage also prevents multi-year "full corpus" analysis. Craxel, levering Black Forest, challenges this status quo and can easily expand to Exabyte scale data, regardless of storage medium, enabling the analysis of an enterprises full corpus of data.
BFDB’s advantage comes from Craxel’s algorithms so we let AWS handle undifferentiated infrastructure work.
To reduce cost, Amazon S3 stores large historical datasets at object-storage instead of on always-on compute and autoscaling node groups in Amazon EKS scale compute as needed. We use Amazon SQS to handle pipeline coordination instead of developing custom queue logic.
BFDB engineering work stays focused on indexing, graph construction, and query performance instead of maintaining infrastructure.
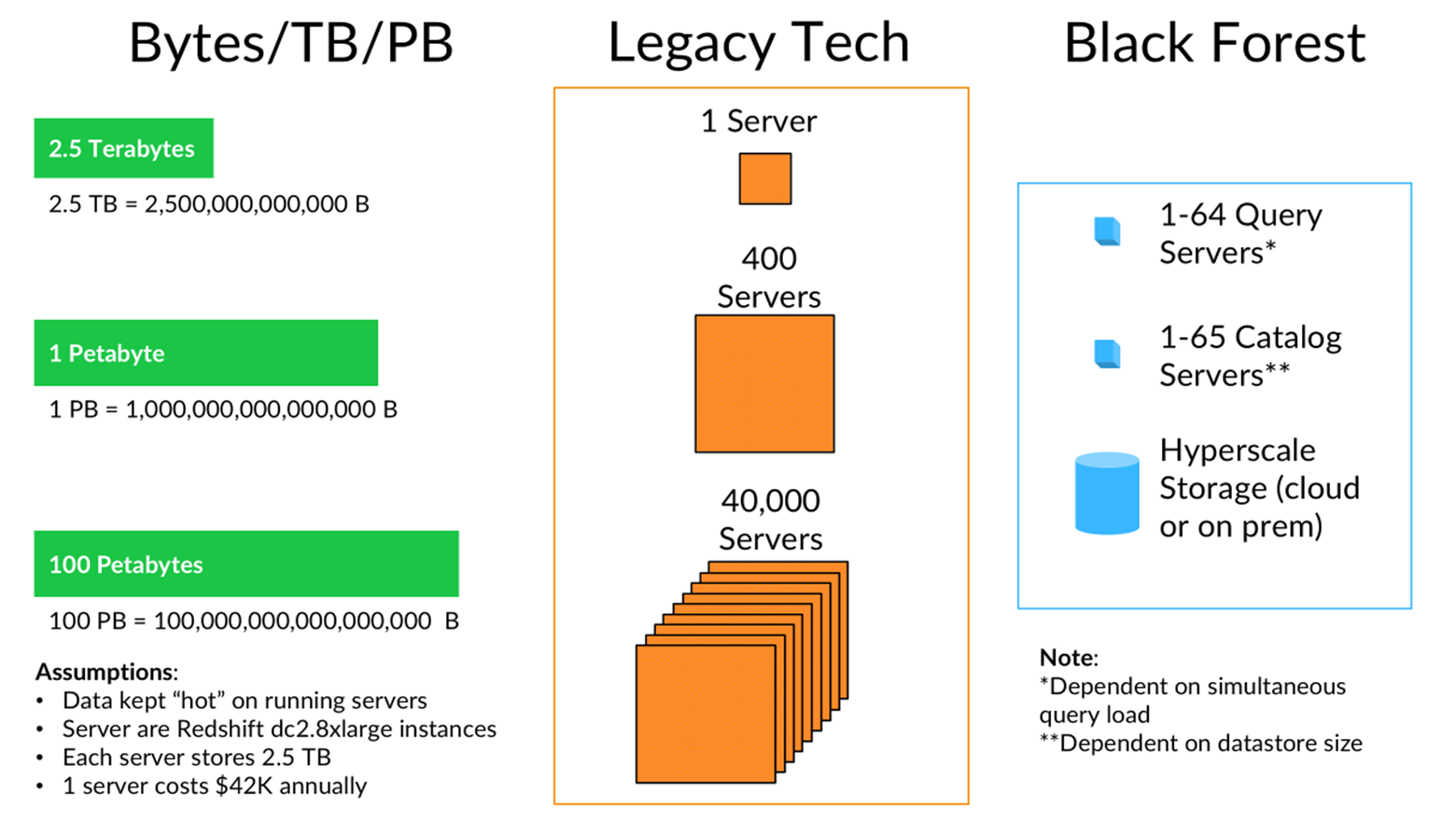
Our patented algorithm “Organizing information using hierarchical data spaces” - stores data in a precisely hashed location (like a GPS for data) – enabling us to use significantly less compute (80%) and commodity storage (i.e. S3) and still enable “hot” access to massive volumes of data at the fraction of the cost for existing brute force solutions.
Our use of on-demand capacity lowers energy consumption and drives sustainability.
In addition to on-demand provisioning, our Multi-Dimensional hash requires much less compute than traditional "brute force" approaches.
For critical use cases that require very low latency access to data, including prominent examples like powering agentic AI or delivering real-time product recommendations, the options provided by legacy technology are limited. They typically require partitioning data over huge server clusters, leading to the risk of spiraling costs as data grows. Black Forest breaks this paradigm by providing low latency access to vast quantities of data that has been organized for rapid access from low-cost hyperscale storage. This can reduce the compute, OPEX and associated energy by as much as 90%
BFDB handles line-speed ingest, graph construction, vector indexing, fast query, and compartmentalized access to the data itself, while AWS provides the production environment around that engine. The production environment includes workload isolation, runtime security, recovery from failure, monitoring, and cost control.
AWS lets Craxel spend its effort on the database instead of the scaffolding.