ChatGPT, Claude, Grok and Gemini trained their models on the open Internet to provide fast and accurate Generative Artificial Intelligence (AI) to the public. In the past few years, enterprises piloted small prototypes that use private copies of Large Language Models (LLM) connected to their proprietary data. They use the Retrieval Augmented Generation (RAG) architecture to drive these enterprise-data-aware LLM. In the next year, your company, your customers, and your competitors will promote these pilots to full-scale enterprise services. This blog post will walk you through some of the landmines you might face in deploying large scale enterprise AI. This post will give you an authoritative position to tune and optimize enterprise AI, which will increase your standing among your peers, customers, leadership, and industry.
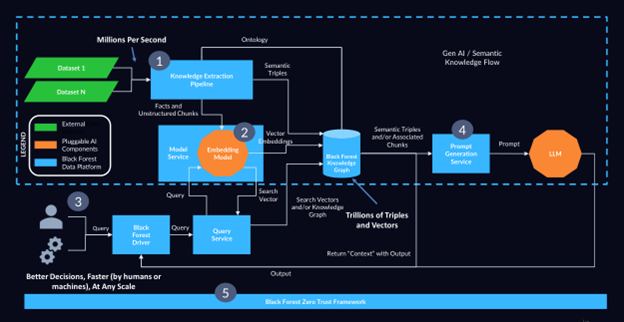
Most enterprise AI focuses on vector-driven RAG. They use an embedding service to represent unstructured data (PDFs, email, documents) in the form of mathematical information (vectors). But an embedding-only approach leads to latency (slow responses), token waste, and security exposure.
Embeddings allow RAG to find semantically related (similar meaning) items even when users use the wrong words. Knowledge graphs, however, store relationships. This allows the AI to map, for example, customers with contracts, users with roles, alerts to incidents, and documents to owners.
Time Series Knowledge Graphs add event order, state change, and history. It answers what happened first, what changed, and ground truth at any given moment. Relationships over time allow you to identify fraud rings, hacker networks, and customer personas.
Embedding-only enterprise AI faces the following problems:
Slow response times
Vector retrieval introduces bottlenecks. In prototypes and benchmarks, vector embeddings appear fast enough. Production environments, however, add filters, ACLs, tenant boundaries, recency rules, and re-ranking. All these introduce latency, to the order of double-digit minutes to hours. This latency disappoints users who love the responsiveness of the public AI offerings.
Poor retrieval and filtering
Architects must raise the top-k (data returned) to avoid missing salient information. They cast a wide net. This fills the prompt with noise, which both wastes tokens and increases the likelihood of hallucinations.
Multi-security document retrieval
Enterprise data sits at multiple access levels. Sources can hold public, role-based, PII, proprietary, and/or secret data. Similarity search alone cannot guarantee the right user sees the right data and nothing else.
Fully homomorphic encryption allows you to search encrypted data, which helps de-risk data leakage. FHE, however, requires massive compute times, and will inject unsustainable latency into prompts. Most teams cannot absorb that latency in a production AI workflow.
Embeddings help with sloppy queries. Their semantic ability will retrieve documents with the intended meaning. KG solve relationships and structure. They model the business path behind the answer.
KG can identify the following paths and their associated records:
• Fraud Workflow: Account -> Transaction -> Merchant -> Alert -> Case
• Refund Workflow: Customer -> Order -> Payment Method -> Refund -> Analyst
• PO Workflow: Vendor -> Contract -> Invoice -> Approval -> Audit Trail
While useful, KG alone prove too rigid for most users. Embeddings and KG together bring the tightest information set to the context window.
An enterprise AI with KG and embeddings requires a heterogeneous backend that can handle graph, time series, vector, SQL and Geospatial searches.
The stack must accommodate:
• Object storage for a durable base layer
• Ingest for parsing, metadata extraction, entity extraction, timestamps, and embeddings
• Graph for entities, relationships, lineage, and policy
• Time series for events, telemetry, and state change
• Vector index for semantic recall
• SQL for structured joins and aggregates
• Geospatial for routes, sites, branches, and service areas
• Identity and policy enforcement in the query path, before prompt assembly
• Searchable encryption to keep stored data encrypted and searchable
• Observability for AI engineers to inspect data retrieval, ranking and usage
Most enterprises today deploy purpose-built databases for each modality, including separate DB for vectors, time series, graph, SQL, and Geospatial. They then hire a dedicated team of Data and AI Engineers to integrate the stacks into a common data layer. Craxel brings together all modalities in one knowledge infrastructure. They provide fusion of time series, graph, vector, SQL, and geospatial embeddings.
• Low Cost/Performance Ratio - 100x faster yet 80% less expensive than competitors
• Novel solution to the hash collision problem which obviates the need to "walk" or re-balance the B-Trees. This yields fast Embedding lookup
• Patented High Performance Serachable Encrytion (HPSE) 100x faster than Fully Homomorphic encryption, with keys held in client, only encrypted data in storage. Users require a key to get data to the prompt.
• Sorted Hash at Gbps+ ingest speed
• No need for "cold storage" - can search PB, EB of data on object store at O(1). Only Network (NW) data retrieval adds to latency
• No Data Rights/ Walled Garden. The customer owns their data and can plug in BFKI to enhance vs. replace their current infrastructure.
Slow or bloated retrieval yields unresponsive, wasteful, and inaccurate enterprise AI. Proper enterprise retrieval must navigate connected, time-bound, and permissioned systems. Tight, focused retrieval delivers small, clean context to the AI. This decreases OPEX and response time. Use both KG and Embeddings to give your enterprise AI users the best experience.