
Authored by John Sobanski, Chief Knowledge Engineer.
Enterprise AI has advanced rapidly over the past several years, but most organizations still face the same underlying problem: their data infrastructure was never designed to support intelligent retrieval at modern scale.
Large language models can generate impressive outputs, but enterprise systems continue to struggle with a more fundamental challenge, securely finding the right information across fragmented, unstructured, and continuously expanding datasets.
For most organizations, enterprise knowledge remains trapped across disconnected repositories, documents, databases, messaging systems, logs, and operational platforms.
Retrieval is slow, governance is inconsistent, and assembling context in real time remains difficult.
The challenge becomes even more complex in environments that require strict security controls, auditability, and policy enforcement. Whether the workflow involves legal discovery, intelligence analysis, regulatory compliance, internal investigations, or public records requests, organizations are ultimately trying to solve the same problem:
Traditional architectures struggle because they were designed primarily for storage and analytics, not contextual retrieval.
Craxel’s Black Forest Infrastructure approaches the problem differently. Instead of treating retrieval, governance, graph analytics, semantic search, and AI context generation as separate systems, Black Forest unifies them into a single knowledge infrastructure layer designed for secure enterprise-scale retrieval.
Most enterprise infrastructure was designed for storage, transactional processing, and analytics not for contextual retrieval across massive, fragmented datasets.
Over time, organizations accumulated data across disconnected repositories, cloud platforms, messaging systems, databases, operational applications, and document stores. Each system evolved independently, often with its own access controls, schemas, indexing methods, and governance policies.
As a result, enterprise knowledge became fragmented.
Critical context is now distributed across unstructured documents, relational systems, logs, communications platforms, and operational datasets that were never designed to work together as a unified retrieval environment. This fragmentation creates both operational and security challenges.
Traditional enterprise search systems were built primarily around keyword indexing and isolated repositories. Modern AI systems often attempt to compensate by performing broad retrieval across enterprise content before constraining outputs later in the inference pipeline.
At small scale, this approach can appear effective.
At enterprise scale, it becomes increasingly inefficient.
As data volumes grow, brute-force retrieval models create escalating infrastructure costs, slower query performance, governance complexity, and greater exposure risk. Organizations struggle not only to find relevant information, but also to determine whether the retrieved information is accurate, authorized, current, and contextually complete.
The challenge is no longer simply storing enterprise data.
The challenge is contextual retrieval, the ability to retrieve the right information, with the right relationships, provenance, timelines, and access controls, at the moment it is needed.
This problem becomes especially difficult in environments that require strict auditability, disclosure controls, and explainability.
Legal discovery, intelligence analysis, regulatory compliance, incident response, internal investigations, and enterprise AI systems all depend on the ability to rapidly identify highly relevant information across distributed environments while maintaining policy enforcement and minimizing unnecessary data exposure.
Most traditional architectures were never designed for this level of interconnected retrieval complexity.
Craxel’s Black Forest Infrastructure approaches the problem differently.
Rather than treating graph analytics, semantic search, vector retrieval, governance, encryption, and AI context generation as separate systems, Black Forest unifies them into a single knowledge infrastructure layer optimized for secure enterprise-scale retrieval.
The result is an environment where relationships, provenance, security controls, and contextual relevance are embedded directly into the retrieval process itself.
Instead of relying on brute-force scans across disconnected repositories, Black Forest creates a continuously updated knowledge infrastructure that combines:
The result is a platform capable of rapidly identifying relevant information while preserving provenance and contextual relationships.
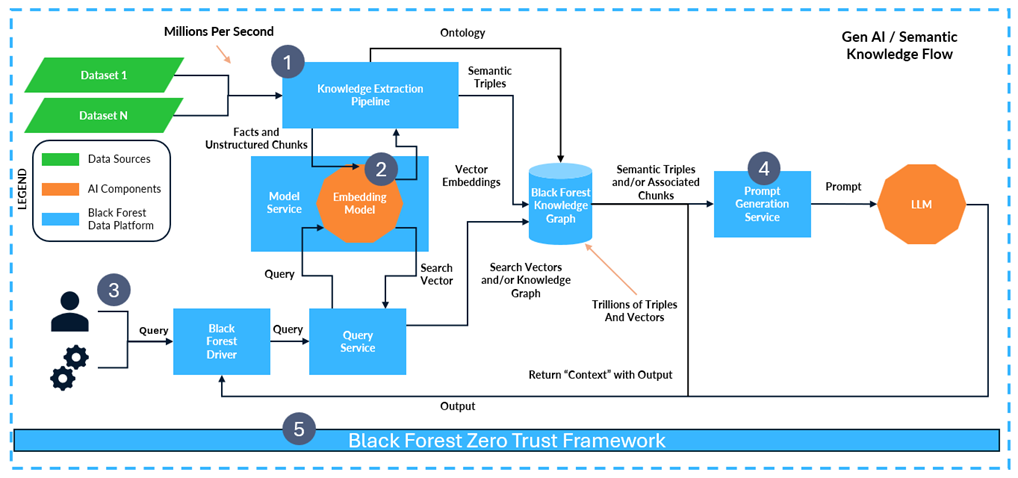
Black Forest prepares enterprise data through two complementary pipelines that work together to create both structured understanding and semantic retrieval capabilities.
The first pipeline focuses on graph construction. Using Named Entity Recognition (NER), Relationship Extraction (RE), Entity Resolution (ER), and canonicalization, the system transforms unstructured content into a normalized knowledge graph.
Instead of treating documents as isolated files, the platform captures relationships between people, systems, organizations, events, and timelines. This creates a navigable contextual layer across the enterprise.
The second pipeline focuses on semantic retrieval. The same enterprise data is embedded into vector representations that support semantic search and Retrieval Augmented Generation (RAG). Rather than depending solely on exact keyword matches, the system retrieves information based on meaning, similarity, and contextual relevance.
Together, the graph and embedding pipelines allow Black Forest to combine symbolic reasoning with semantic understanding. The platform can simultaneously traverse relationships, identify temporal connections, and retrieve semantically related information from large-scale unstructured datasets.
Instead of returning massive collections of loosely related files, the platform produces focused evidence sets tied directly to source documents, entities, timestamps, and authorization policies.
This dramatically reduces retrieval overhead while improving contextual precision for both analysts and AI systems.
Most enterprise retrieval systems were designed around relational databases or large-scale brute-force scanning architectures.
As data volumes increase, these approaches become increasingly expensive and operationally inefficient.
Large cloud data warehouses often rely on massively parallel scans across distributed infrastructure. While effective for broad analytics workloads, this architecture can become prohibitively expensive for selective retrieval across continuously growing environments.
The challenge becomes even more pronounced when organizations attempt to combine:
In most environments, these capabilities require multiple disconnected systems.
Black Forest was designed to unify them within a single infrastructure layer.
At the core of Black Forest is Craxel’s probabilistic indexing approach and distributed OLTP database architecture. The platform was designed around an indexing model that preserves hierarchical relationships across data types while supporting complex access patterns with constant-time indexing behavior.
Unlike traditional systems that separate graph databases, vector stores, time-series platforms, and relational infrastructure into independent stacks, Black Forest treats multiple forms of enterprise data through a unified spatial logic.
Knowledge graphs, vector embeddings, time-series records, relational structures, and geospatial information can all coexist within the same infrastructure layer.
This architecture allows organizations to query across modalities without stitching together multiple disconnected platforms.
The indexing model is equally important. In many large-scale environments, query cost grows with the total size of the dataset, forcing organizations into increasingly expensive, compute-intensive architectures.
Black Forest is designed so retrieval cost scales primarily with the amount of relevant information returned rather than total data volume.
That distinction becomes increasingly important at petabyte scale. Craxel reports ingest rates reaching 1 Gbps on commodity cloud infrastructure while supporting graph traversal, vector similarity search, SQL, SPARQL, nearest-neighbor retrieval, and interval queries within the same environment.
Rather than relying on brute-force scans across massive server clusters, the system focuses on selective retrieval efficiency. This enables organizations to maintain performance and reduce infrastructure overhead even as enterprise data volumes continue to expand.
One of the most difficult challenges in enterprise AI is controlling data exposure during retrieval.
Many AI systems retrieve broad collections of enterprise content before attempting to filter or constrain outputs. That model creates governance, security, and disclosure risks, particularly in environments containing classified, proprietary, regulated, or personally identifiable information.
Black Forest introduces security directly into the retrieval layer itself.
Through High-Performance Searchable Encryption (HPSE), encrypted enterprise data remains searchable without requiring broad plaintext exposure. The platform combines zero-trust access controls, deterministic retrieval policies, field-level authorization, and cryptographic identity management to ensure that only authorized information is surfaced.
This creates a policy-driven context layer between enterprise data and internal AI systems. Rather than exposing large datasets to models, the infrastructure retrieves only the exact authorized context required for a given operation.
The result is improved auditability, lower inference risk, reduced overexposure, and stronger governance for enterprise AI deployments operating at scale.
A major differentiator of the platform is the fusion of:
This enables organizations to reason not only about entities and relationships, but also about how events evolve over time.
The infrastructure supports:
The result is a continuously evolving enterprise knowledge layer capable of supporting AI applications with contextual precision.
The next phase of enterprise AI will not be defined solely by larger models or more compute. It will be defined by whether organizations can build retrieval infrastructure capable of securely delivering the right context at scale.
That requires more than storage, search, or analytics alone. It requires infrastructure that can unify relationships, semantics, timelines, provenance, and policy enforcement into a coherent retrieval layer for both humans and machines.
Craxel’s Black Forest Infrastructure represents an effort to build that layer.
By combining knowledge graphs, semantic retrieval, secure AI access, and high-performance searchable encryption within a unified architecture, the platform aims to transform fragmented enterprise data into operational knowledge infrastructure.
FOIA is one example of where this capability becomes critical. However, the broader implication is much larger.
As organizations attempt to operationalize AI across increasingly complex and sensitive environments, contextual retrieval and governance will become foundational infrastructure challenges.
The organizations that solve them first will define the next generation of enterprise intelligence.